Paper Review
Modular Pluralism: Pluralistic Alignment via Multi-LLM Collaboration (EMNLP 2024)
- -
728x90
https://aclanthology.org/2024.emnlp-main.240/
Modular Pluralism: Pluralistic Alignment via Multi-LLM Collaboration
Shangbin Feng, Taylor Sorensen, Yuhan Liu, Jillian Fisher, Chan Young Park, Yejin Choi, Yulia Tsvetkov. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024.
aclanthology.org
1 Introduction
Background
- LLM alignment은 인간의 가치와 선호를 반영하도록 모델을 조정하는 것을 목표로 함
- 그러나 인간의 선호는 단일하지 않음
- 지역, 문화, 인종, 이념 등에 따라 가치와 기준이 다양함
- 기존의 alignment 방식은 이러한 다원적(pluralistic) 가치들을 제대로 반영하지 못하고, 때로는 오히려 해칠 수 있음
Problem Definition
- 기존 방법들은 LLM을 재학습하거나 구조적으로 수정해야 하므로, 특히 블랙박스 모델이나 이미 학습된 모델에는 적용이 어려움
- 특정 커뮤니티의 관점이 소외되었을 경우 이를 보완하려면 많은 비용이 듬
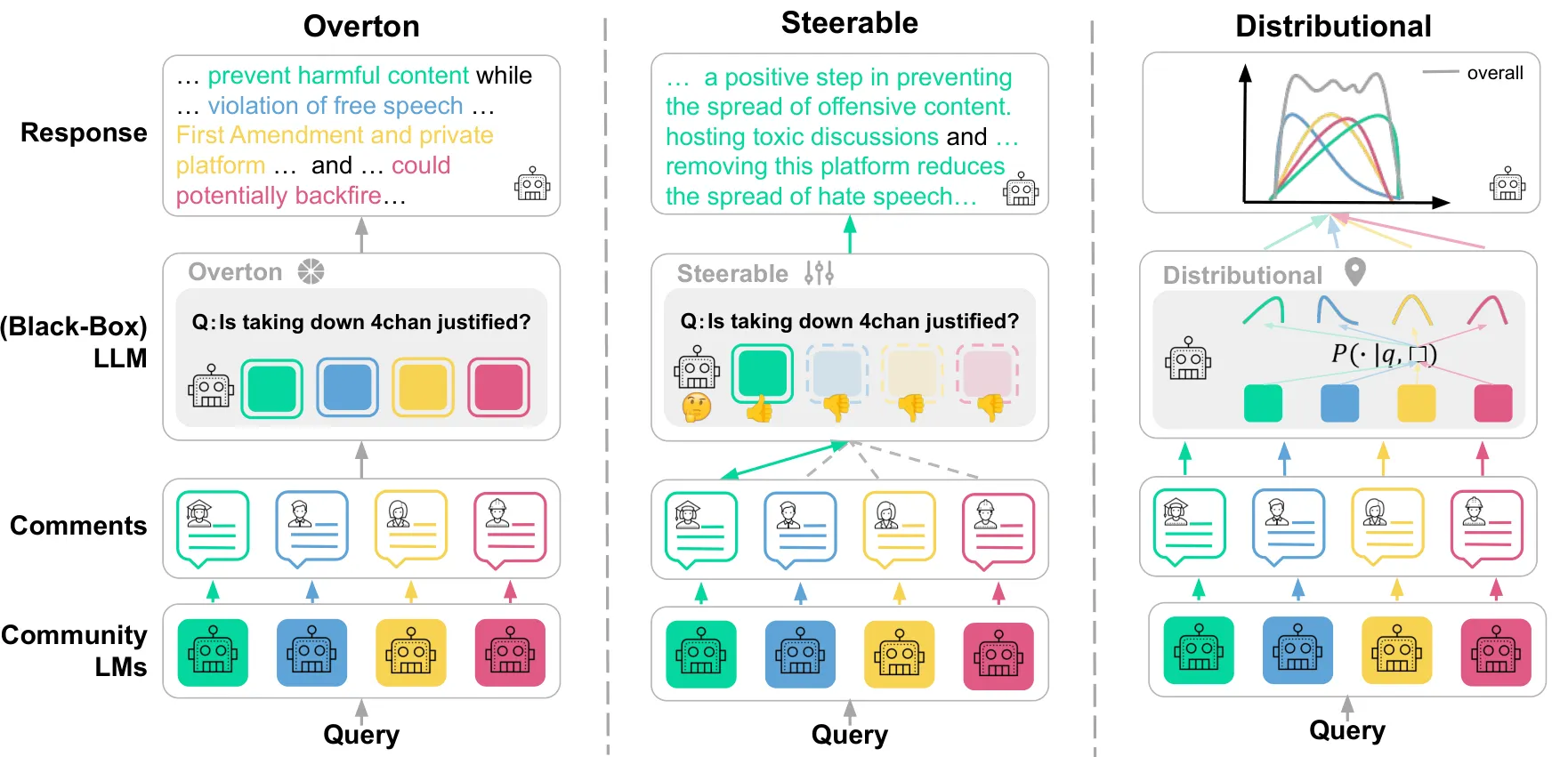
Modular Pluralism
- Multi-LLM 협력 기반의 플러그-앤-플레이(Plug-and-Play) 정렬 프레임워크 제안
- 기존 LLM에 소형 커뮤니티 LMs를 모듈처럼 결합하여 다양한 공동체의 가치와 관점을 반영
- 블랙박스 모델에도 적용 가능하며, 새로운 커뮤니티 LM을 추가함으로써 쉽게 정렬 패치 가능
- Overton Pluralism: 다양한 의견을 제시하고, 블랙박스 LLM이 이를 요약해 응답
- Steerable Pluralism: 사용자가 지정한 속성(예: 문화, 성별 등)에 따라 응답을 조정
- Distributional Pluralism: 인구 분포를 반영하여 응답 분포를 형성
실험 및 성능
- 4개 데이터셋, 6개 작업, 6종의 LLM(오픈소스 및 블랙박스)에 대해 평가 수행
- 주요 성능
- Overton pluralism에서 평균 68.5% 개선
- 속성 기반 조정(steerability)에서 26.6%, 10.4% 향상
- 분포 기반 정렬(distributional)에서도 10.9% 이상 향상
- 또한, 새 커뮤니티 LM을 추가하는 방식으로 소외된 집단의 가치도 쉽게 반영 가능함을 확인
2 Methodology
Modular Framework
- 우리는 LLM의 출력과 토큰 확률(token probabilities)에 접근할 수 있다고 가정하고, 커뮤니티 언어모델(community LMs)의 집합 $C = \{c_1, c_2, \cdots, c_k\}$을 훈련
- 각 커뮤니티 LM($c_i$)는 기존 모델 체크포인트 c를 특정 커뮤니티의 말뭉치 $D_i$에 대해 파인튜닝한 것
- 형식적으로는 $c_i = \text{NLL}(c \mid D_i)$로 표현
- 이들 말뭉치 $\{D_i\}$는 다양한 인구통계, 문화, 사회·정치적 배경을 반영하도록 뉴스, 소셜 미디어 등에서 수집
- 사용자 질의 q가 주어지면, LLM만을 사용하는 대신 소형 커뮤니티 LMs가 먼저 메시지 또는 코멘트 $m_i = c_i(q)$를 생성하고, 이는 LLM이 참조하도록 활용
Overton Pluralism
- 사용자 질의에 대해 다양한 가치와 관점을 반영 필요 → 모든 소형 커뮤니티 언어모델(community LMs)은 각각의 코멘트 $\{m_1, \cdots, m_k\}$를 생성
- 이러한 코멘트들은 사용자 질의 q와 함께 연결되어(concatenated) LLM에 입력되며, LLM은 multi-document summarization system처럼 작동하여 이 다양한 관점을 하나의 일관된 응답으로 종합
$$ response = LLM(q | {m₁, ..., mₖ}) $$
- LLM이 커뮤니티 LMs의 다양한 시각을 충실히 반영할 수 있도록 다음과 같은 프롬프트를 사용
“Please comment on a given situation with the help of the following passages.”
(다음의 글들을 참고하여 주어진 상황에 대해 의견을 제시해주세요.)
Steerable Pluralism
- 사용자 질의에 특정 가치나 속성(attribute)을 명시했을 때, 그 방향으로 정확하게 응답을 조정(steer)할 수 있어야 하며, 이는 다양한 LLM 사용자 집단의 자율성(agency)을 존중하는 데 중요
- LLM의 역할은 주어진 속성(attribute)을 가장 잘 반영하는 커뮤니티 LLM의 메시지를 선택
Process
1. 커뮤니티 LMs 응답 생성
- 주어진 질의 q에 대해, 커뮤니티 언어모델 $\{c_1, c_2, ..., c_k\}$는 다음과 같은 메시지(코멘트)를 생성
$$ \{m_1, m_2, ..., m_k\} $$
2. 속성 기반 선택
- LLM은 속성 a∈A에 따라 위 메시지 중 가장 적절한 것 하나를 선택함
$$ m = \text{select}(\{m_1, ..., m_k\} \mid \text{LLM}, q, a) $$
사용된 프롬프트
"Which of the following comments best reflect <attribute>?"
3. 조건부 응답 생성
- 선택된 메시지 m과 속성 a를 바탕으로 최종 응답 생성
$$ \text{response} = \text{LLM}(q \mid m, a) $$
Distributional Pluralism
- 현실 세계 인구의 분포와 상응하는 응답 분포(response distribution)를 생성
- LLM은 각 커뮤니티 LM의 메시지에 대해 **개별적으로 응답 확률 분포 $\{d_1, ···, d_k\}$**를 생성
Process
- LLM이 각 메시지에 조건화된 확률 분포 생성
- 각 메시지에 대해 LLM이 별도의 확률 분포 $d_i$ 생성
- 커뮤니티 사전 확률 설정
- 각 커뮤니티에 대한 사전 확률 $w_i$ 설정
- 최종 응답 분포 계산
- 각 분포에 가중치를 곱해 최종 분포 d 계산
- 위 과정으로 LLM은 각 커뮤니티 LM에 조건화된 다양한 분포를 생성하고, 이를 조합하여 현실 세계 인구의 의견 분포를 반영하는 응답 생성
3 Experimental Settings
Models
- LLAMA2 계열
- LLAMA2-7B
- LLAMA2-13B ⭐ (주요 실험 모델)
- LLAMA2-70B
- LLAMA3-8B
- GEMMA-7B
- ChatGPT ⭐ (주요 실험 모델)
- ChatGPT: 대형 블랙박스 모델
- LLAMA2-13B: 오픈소스 기반 모델
- 각 모델은 unaligned (base) 버전과 aligned 버전 모두 평가에 사용됨
- 본문에서는 대표적으로 LLAMA2-13B와 ChatGPT 중심으로 결과 분석
- 나머지 모델에 대한 실험 결과는 Appendix A에 제시됨
Implementation
- Community LM 구성
- 초기 체크 포인트: Mistral-7B-Instruct-v0.2
- 학습 방식
- LoRA 기반 parameter-efficient finetuning 사용
- 커뮤니티별 코퍼스로 fine-tune
- 사용한 커뮤니티 코퍼스 (Feng et al., 2023) - 정치적 성향이 반영된 6개 코퍼스
- 좌파 성향 뉴스
- 중도 성향 뉴스
- 우파 성향 뉴스
- 다양한 소셜 미디어 문서 포함
- 서로 다른 관점을 반영하는 6개의 Community LMs 생성
- 이들 모델은 대형 LLM과 협업하여 Pluralism 모드 구현에 활용됨
Baselines
- vanilla
- LLM을 별도 조정 없이 그대로 사용하여 프롬프트 응답
- prompting
- 프롬프트 앞에 지시문을 추가하여 다원주의(pluralism)를 유도
- 예: "Make sure your response reflects diverse values and perspectives."
- mixture-of-experts (MoE)
- 사용자 질의를 가장 적합한 커뮤니티 LM에 라우팅
- 선택된 커뮤니티 LM이 comment를 생성 → 해당 comment를 질의 앞에 붙여 LLM 입력으로 사용하여 응답 생성
Tasks and Datasets
Overton Pluralism (다양한 관점 반영 평가)
Task 1: NLI 기반 평가
- Dataset: Value Kaleidoscope (VK)
- 목표: LLM 응답이 얼마나 다양한 가치(Values)를 반영하는가?
- 방법: NLI 모델을 이용하여 VK에서 제시한 상황에 대해 얼마나 많은 가치들이 LLM 응답에 반영되는지를 측정
Task 2: Human 및 GPT-4 평가
- Dataset: Value Kaleidoscope (VK)
- 목표: LLM 응답이 다원적 가치와 관점을 얼마나 잘 반영하는가?
- 방법:
- Human 평가: 사람 평가자가 다원주의를 더 잘 반영한 응답 선택
- GPT-4 Judge 평가: GPT-4를 평가자로 설정해 승/패/무승부 비율 측정
Steerable Pluralism (지정된 속성으로 유도하는 능력)
Task 3: VK 기반 값 유도
- Dataset: Value Kaleidoscope (VK)
- 목표: 주어진 가치(Value)에 따라 상황에 대한 태도 (찬성/반대/중립)를 분류
- 지표: Accuracy, Balanced Accuracy, Macro F1
Task 4: OpinionQA 기반 속성 유도
- Dataset: OpinionQA
- 목표: 특정 인구 속성(예: 교육 수준, 정당 소속 등)에 따라 설문 응답을 유도
- 지표: 전체 및 속성별 정답률 (LLM의 응답이 해당 속성 그룹의 실제 응답과 일치하는지)
Distributional Pluralism (인구 비율 기반 분포 반영)
Task 5: MoralChoice 기반 분포 평가
- Dataset: MoralChoice
- 목표: 도덕적 선택 상황에서 모호성 수준에 따라 선택 분포를 조절할 수 있는가?
- 지표: Jensen–Shannon Distance (예: [1, 0] 또는 [0.5, 0.5] 분포의 유사성 비교)
Task 6: GlobalOpinionQA 기반 국가별 여론 분포 반영
- Dataset: GlobalOpinionQA
- 목표: 주어진 국가에 따라 여론 분포를 반영한 응답 생성
- 지표: LLM 응답 분포와 실제 국가 여론 분포 간 Jensen–Shannon Distance 계산
4 Results
MODULAR PLURALISM better covers diverse values and perspectives. (Overton w/ NLI 평가 결과)

- MODULAR PLURALISM은 다양한 가치와 관점의 반영 측면에서 가장 높은 성능을 기록함
- 최대 50.3% 향상된 Value Coverage 달성
- 기존 prompting 기반 접근법은 안정적인 향상 효과 없음
- 템플릿화된 비자연적인 응답 ("On one hand, ..., on the other hand, ..., therefore ...") 을 유도하는 경향 ➜ MODULAR PLURALISM은 community LMs의 다양한 관점을 자연스럽고 응집력 있게 요약하는 응답 생성
- aligned LLM과 함께 사용할 경우 성능이 특히 우수함
- 예: ChatGPT의 경우 27.2% 향상
- 이는 MODULAR PLURALISM의 요약 역할(LMs 간 comment 통합)을 aligned 모델이 더 잘 수행하기 때문
- 하지만 unaligned LLM에도 성능 향상이 명확히 나타남 ➜ 모든 유형의 LLM에서 효과적
Human and GPT-4 evaluation find that MODULAR PLURALISM produces more pluralistic responses. (overton w/human and GPT-4 evaluation)

- MODULAR PLURALISM은 인간 평가자와 GPT-4 모두로부터 더 높은 pluralistic 응답 품질을 인정받음
- 모든 기준선(baselines)에 대해 일관된 우세(win rate) 기록
- 정량적 성과
- Human Evaluation 기준: MODULAR PLURALISM이 기준선 대비 45.8% 높은 win rate
- GPT-4 Evaluation 기준: 기준선 대비 16.5% 높은 win rate
- 평가 신뢰도
- Fleiss’ Kappa = 0.4678 → 다섯 명의 인간 평가자 간 중간 정도의 일치 (moderate agreement)
- 비교 대상 중 Prompting 방식이 가장 경쟁력 있었지만, 여전히 MODULAR PLURALISM에 밀림
- 결론: NLI 평가 결과와 함께, MODULAR PLURALISM은 보다 다양하고 균형 잡힌 응답을 생성할 수 있는 Overton pluralistic alignment에 탁월한 방법임이 입증됨
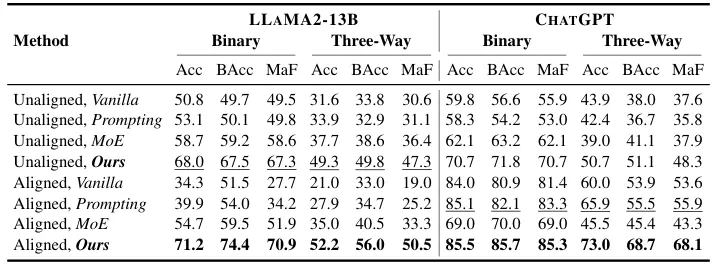
MODULAR PLURALISM offers stronger steerability for value-specific contexts. (Steerable w/ Value Kaleidoscope)
- 목표: 주어진 상황에 대해 특정한 value(가치)를 중심으로 LLM의 응답을 정확히 조정(steer)할 수 있는 능력 평가
- 평가 세팅
- Three-way 분류: support / oppose / either
- ambiguous한 선택지(either)가 추가되어 더 어려운 평가 조건
- Binary 분류: support / oppose
- 보다 명확한 구분을 가진 설정
- Three-way 분류: support / oppose / either
- 결과
- Three-way classification
- Balanced Accuracy (BAcc): 최대 23.8% 향상
- Macro F1 Score: 최대 21.8% 향상
- Binary classification
- MODULAR PLURALISM이 기준선 대비 평균 15.1% 향상
- Three-way classification
MODULAR PLURALISM are more faithful to personas of socio-political attributes. (Steerable w/ OpinionQA)

- 목표: 주어진 사회·정치적 속성(demographic attribute)에 따라 LLM이 응답을 얼마나 잘 조정(steer)할 수 있는지를 평가
- 전체 정확도 기준
- MODULAR PLURALISM이 가장 높은 성능을 달성
- 기존 최고 성능 기준선 대비 평균 8.9% 향상
- 8가지 속성별 분석 결과:
- 정당 속성(political party)에서 가장 큰 향상폭: 12.8%
- 이는 기본 community LMs가 정치적 커뮤니티 기반으로 학습되었기 때문
- MODULAR PLURALISM은 다양한 사회·정치적 속성에 따라 LLM 출력을 세밀하게 조정 가능
- 특히, 특정 커뮤니티 기반 LMs를 추가하여 이전에 과소대표되었던 집단을 정밀하게 보완하는 "수술적 정렬" 가능성 입증
- 이는 향후 다양한 커뮤니티 LM을 모듈형으로 추가해가는 방향으로 확장 가능
MODULAR PLURALISM strikes a balance between low and high ambiguity moral scenarios. (Distributional w/MoralChoice)

- 목표: 도덕적 상황에 대한 모델의 확신 정도가 상황의 모호성 수준에 따라 잘 조정되는지를 평가(예: 명확한 상황에서는 확신 있게, 모호한 상황에서는 불확실하게 반응해야 함)
- 기존 LLM 성향
- Aligned LLMs (ex. ChatGPT)
- 낮은 모호도 상황에서 낮은 엔트로피 → 확신이 강함 (좋음)
- 높은 모호도 상황에서도 여전히 확신 → 과신(overconfidence) → 분포 왜곡 심함
- Unaligned LLMs
- 반대로 확신 부족으로 인해 고·저 모호도 모두에서 불명확한 분포를 가짐
- Aligned LLMs (ex. ChatGPT)
- MODULAR PLURALISM 도입 시
- 두 극단의 경향을 완화하며 중간 지점으로 이동
- 가장 낮은 분포 거리(Jensen-Shannon distance) 기록
- 기존 최고 baseline 대비 평균 16.1% 감소
- 이는 다양한 커뮤니티 LM들이 제공하는 합의적/충돌적 의견을 반영한 결과
- MODULAR PLURALISM은 모호도에 따른 적절한 불확실성 표현을 가능하게 하여, 기존 모델들의 과신 또는 과도한 불확실성 문제를 완화함
MODULAR PLURALISM better models nationality distributions. (Distributional w/ GlobalOpinionQA)

- 목적
- 세계 각국의 여론 분포와 LLM의 응답 분포가 얼마나 잘 일치하는지 평가
- 특히, 국가별 문화적 다양성에 따른 응답 분포 정합성 측정
- MODULAR PLURALISM 성능
- 평균적으로 Jensen–Shannon 거리 14.9% 감소 → 더 현실적인 여론 분포에 근접함을 의미
- 이는 커뮤니티 LMs에 다양한 뉴스 및 소셜미디어 기반 코퍼스를 도입했기 때문
- Unaligned LLM > Aligned LLM
- 비정렬 LLM이 정렬된 LLM보다 평균 11.5% 더 낮은 J-S 거리
- 이는 기존 정렬 기법이 문화적으로 편향되거나 오히려 정렬 오류(misalignment)를 유발한 결과로 해석됨
국가 성능 향상 (J-S 거리 감소율)
| 🇺🇸 미국 | 25.8% (가장 큰 향상) |
| 🇳🇬 나이지리아 | 9.3% (가장 낮은 향상) |
- 원인 분석
- 현재 커뮤니티 LMs가 미국 중심 뉴스 및 Reddit 데이터에 기반
- 서구권 이외의 문화적 다양성은 충분히 반영되지 않음
- MODULAR PLURALISM은 다양한 국가의 여론 분포에 더 잘 맞는 응답을 생성
- 향후에는 비서구권 문화를 반영한 커뮤니티 LM 개발 필요성이 강조됨 → Section 5에서 대안 제시 예정
5 Analysis
Message Faithfulness
MODULAR PLURALISM의 커뮤니티 LM 반영 정도 분석
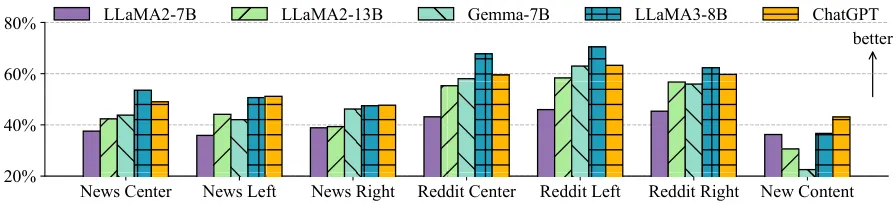
- 분석 목적: LLM이 커뮤니티 LMs의 코멘트를 얼마나 충실히 반영하여 응답을 생성하는지를 확인하기 위해 NLI 모델을 활용하여 평가
- 평가 방법
- 코멘트 반영 여부 (Coverage)
- 커뮤니티 LM이 생성한 코멘트 중 최소 한 문장이 LLM 응답의 문장과 의미적으로 일치(entail)하는가? → 해당 코멘트가 응답에 반영된 것으로 간주됨
- LLM 독자 생성 문장 비율 (New Content)
- LLM 응답 중 어떤 문장이 어느 커뮤니티 LM의 코멘트로도 entail되지 않는 경우 ****→ LLM이 새로운 내용 추가한 것임
- 코멘트 반영 여부 (Coverage)
- 주요 결과
- 코멘트 반영률 (Coverage Rate)
- 평균 51.2% 수준에서 커뮤니티 LM의 코멘트가 LLM 응답에 반영됨
- 소셜 미디어 기반 커뮤니티 LM(Reddit): 평균 57.7%
- 뉴스 기반 커뮤니티 LM: 평균 44.7% → Reddit 기반 코멘트가 더 잘 반영
- 이유: 독창적이고 비정형적인 표현이 많아 응답 생성에 유용
- 이념적 편향 여부
- 좌/중도/우 성향 커뮤니티 LM 모두 고르게 반영됨
- 예외적으로 LLAMA3-8B 모델이 우성향 커뮤니티 LM을 약간 덜 반영, 그러나 통계적으로 유의미하지 않음
- LLM 독자 생성 문장 비율
- 평균 33.8%의 문장은 커뮤니티 LM 코멘트가 아닌 LLM 자체 생성 내용
- 특히 성능이 좋은 LLM들(LLAMA3-8B, ChatGPT)은 커뮤니티 LM 코멘트 반영률도 높고 LLM 자체 콘텐츠 생성 비율도 높음
- 더 강력한 LLM일수록 다문서 요약 능력과 자체 가치 보완 능력이 모두 뛰어남
- 코멘트 반영률 (Coverage Rate)
Cultural Community LMs
MODULAR PLURALISM의 커뮤니티 LM 다양화 실험(CultureBank)

- 목적
- 기존에는 서구권 뉴스 & Reddit 기반 커뮤니티 LMs만 사용됨 (Feng et al., 2023)
- 더 광범위한 문화적 대표성을 반영하기 위해, CultureBank(Shi et al., 2024) 코퍼스를 기반으로 한 문화적 커뮤니티 LMs를 추가로 훈련
- 세부 설정
- CultureBank 텍스트를 대륙별로 분할하여, 각 대륙의 문화 규범을 대표하는 커뮤니티 LM을 구성
- 두 가지 실험 방식
- 기존 perspective community LMs를 cultural community LMs로 전면 대체
- 혼합 사용 (perspective + cultural)
- 주요 결과과제 문화적 LM 도입 효과
Steerable-OpinionQA (미국 중심 여론조사 정렬) 오히려 정렬 성능 저하됨→ 미국 중심 속성 정렬에 글로벌 문화 정보가 방해 요인 Distributional-GlobalOpinionQA (전 세계 여론 분포 정렬) 혼합 설정에서 성능 가장 우수→ 글로벌 문화적 시각 확장이 효과적 - 결론 및 시사점
- 문화적 커뮤니티 LM 도입은 목적에 따라 긍정/부정 영향이 달라짐
- 특정 국가(미국) 기반 정렬에는 오히려 방해 가능성 존재
- 그러나, 글로벌 관점이 요구되는 분포 정렬 과제에는 큰 도움이 됨 ⇒ MODULAR PLURALISM은 문화적 다양성 확장을 통해 서구 중심 편향을 극복하고 더 공정한 정렬을 실현할 수 있는 잠재력이 있음
Patching LLMs’ Gaps in Pluralism
MODULAR PLURALISM의 문화 기반 커뮤니티 LM 추가 실험
- 기존 LLM들은 광범위한 정렬 과정을 거치지만, 특정 문화 및 커뮤니티는 여전히 과소대표됨 (Naous et al., 2023; Rao et al., 2024)
- 이로 인해 일부 지역/커뮤니티에 대한 정렬 성능이 떨어지는 pluralism gap 발생
해결 방안
- 서구 중심 편향을 완화하기 위해, 기존 perspective 커뮤니티 LM pool에 아시아 문화 커뮤니티 LM 또는 아프리카 문화 커뮤니티 LM을 추가로 플러그인
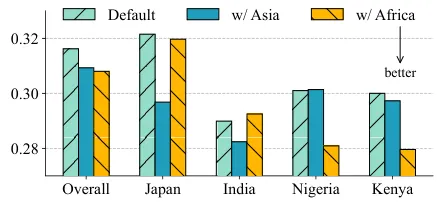
실험 구성 및 결과 (GlobalOpinionQA 재평가)
- 대상 국가
- 아시아: 일본, 인도
- 아프리카: 나이지리아, 케냐
- 결과
- 아시아 문화 LM 추가 시 → Jensen-Shannon 거리 5.2% 감소
- 아프리카 문화 LM 추가 시 → J-S 거리 6.7% 감소
- 기존 서구권 커뮤니티에 대해서는 정렬 성능 유지됨
시사점
- MODULAR PLURALISM은 새로운 커뮤니티 LM을 선택적으로 추가하여 특정 문화권의 정렬 성능을 보완 가능
- 서구 중심 편향을 줄이고, 세계 각 지역의 관점을 반영하는 공정한 LLM 구축에 기여함 → Pluralism gap을 ‘모듈형 패치’ 방식으로 실용적이고 정밀하게 해결할 수 있음
7 Conclusion
- MODULAR PLURALISM는 다중 LLM 협업 프레임워크로, 다양한 커뮤니티의 가치와 관점을 반영한 pluralistic alignment를 실현함
- 기본 LLM은 작고 특화된 community LM들과 상호작용하며, Overton / Steerable / Distributional 정렬 목표를 다양한 방식으로 달성
- 광범위한 실험 결과
- 다양한 모델과 평가 데이터셋에서 pluralism 성능 향상
- 기존 LLM이 잘 다루지 못하던 저대표(underrepresented) 커뮤니티에 대한 정렬 성능 향상 가능 → community LM을 플러그인으로 쉽게 추가 가능
Limitations
- 커뮤니티 정의의 제한
- 현재는 perspective-informed (정치적 성향 등) 및 culture-informed (지역/문화권 중심) 커뮤니티에 집중
- 미래에는 다른 커뮤니티 정의 (예: 종교, 성소수자, 장애인 등) 기반 LM도 확장 가능
- 추론 비용 증가
- 커뮤니티 LM들을 함께 활용하기 때문에 기본 프롬프트 방식보다 계산 비용 높음
- 하지만 수백억 파라미터 LLM을 사용할 경우, 여러 개의 7B 커뮤니티 LM 추가는 비용 대비 효과적으로 정렬 품질 향상 가능
- 추후에는 더 작은 LM 기반 community LM 구성을 연구할 계획
- 평가의 한계
- Overton, Steerable, Distributional의 3가지 pluralism을 중심으로 4개 데이터셋, 6개 평가 방식 사용
- 하지만 현실 세계 사용 시나리오와 사람 평가 기반 실험은 부족 → 향후 실사용자 기반 평가 및 윤리 연구 확대 필요
- 커뮤니티 데이터 구축의 어려움
- 커뮤니티 LM 학습을 위해 대표적인 community corpus 수집이 필요
- 기존에는 Reddit, 뉴스 등에서 수집했지만, intersectional community(다중 정체성 공동체)에 대해선 데이터 수집·정의의 어려움이 존재
Future Work
- 소형 community LM 도입, 더 정교한 커뮤니티 정의 및 수집 방안 연구
- 실사용자 기반 평가, 인터랙티브 시나리오, 실시간 동적 정렬 시스템으로 확장 가능성 존재
728x90
Contents
소중한 공감 감사합니다